Raft distributed consensus
State machine replication
Paul Krzyzanowski
February 2020/March 2021
Goal: Create a fault-tolerant distributed algorithm that enables a set of processes to agree on a sequence of events.
Why do we need consensus?
Consensus, or distributed agreement, is a recurring problem in distributed systems design. It is useful for things such as mutual exclusion, where all processes agree on who has exclusive access to a resource, and leader election, where a group of processes has to decide which of them is in charge. Perhaps most importantly, consensus plays a pivotal role in building replicated state machines.
Replicated state machines
Systems fail and the main way that we address fault tolerance is by replication: having backup systems. If one computer fails, another can take over if it runs the same services and has access to the same data.
Replicated state machines are a way to keep multiple systems in an identical state so that the system can withstand the failure of some of its members and continue to provide its service.
A common use for replicated state machines is when distributed systems need a central coordinator. For instance, Google Chubby provides a centralized namespace and lock management service for the Google File System as well as various other services. Apache ZooKeeper serves a similar purpose in coordinating various Apache services, including the Hadoop Distributed File System (HDFS). Big data processing frameworks, such as MapReduce, Apache Spark, and Kafka also all rely on central coordinators.
We refer to these systems as state machines because they are programs that store “state” – data that changes based on inputs received by the programs. Key-value pairs, database updates, and file updates are all common examples of this. Programs are deterministic, meaning that multiple identical copies of the program will all modify their data (“state”) in the same way when presented with the same input
Replicated logs
A replicated state machine is simply a program (state machine) that is replicated across multiple systems for fault tolerance. These systems are commonly implemented using a replicated log. A log is a list of commands that are received and stored by each system. This list of commands is read sequentially from the log and used as input by the program (state machine).
For the state machines to remain synchronized, the commands in the log must be identical and in the same order across all replicas.
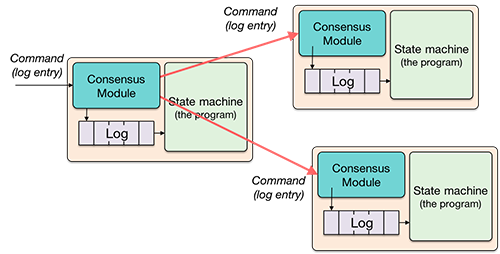
The goal of the consensus algorithm is to keep these logs consistent. To do this, a consensus module runs on each system, receiving commands, adding them to its log, and talking with consensus modules on other servers to forward commands and get agreement on the order of requests. Once a consensus module is convinced that the log is properly replicated, the state machine on each system can process the log data.
Consensus problem
The problem of consensus is getting a group of processes to unanimously agree on a single result. There are four requirements to such an algorithm:
- Validity. The result must be a value that was submitted by at least one of the processes. The consensus algorithm cannot just make up a value.
- Uniform agreement. All nodes must select the same value.
- Integrity. A node can select only a single value. That is, a node cannot announce one outcome and later change its mind.
- Termination. Also known as progress, every node must eventually reach a decision.
The algorithm needs to work as long as a majority of processes are properly working and assumes:
- Some processors may fail. Processes operate in a fail-stop or fail-restart manner.
- The network is asynchronous and not reliable. Messages may be lost, duplicated, or received out of order.
- There is no Byzantine failure. If a message is delivered, it is not corrupted or malicious.
Quorum
The requirement that a majority of processes are operating and accessible over the network is an important part of consensus. This requirement makes it easier to handle network partitions. A partition is when a network gets segmented into two or more sub-networks that cannot communicate with each other. For instance, a cable connecting ethernet switches across two racks may get disconnected or connectivity to a remote data center may be lost.
Should a partition occur, every group of processes may continue working on their own, not propagating data to the systems that they cannot reach and not getting inputs from systems that cannot reach them. As time goes on, these systems are no longer replicas and contain distinctly different data.
In distributed systems, quorum refers to the minimum number of processes that need to be functioning for the entire system to continue operating. By requiring a majority, we can avoid the problem of trying to merge updates from multiple systems coherently by simply having any non-majority groups cease to function.
The other benefit of a majority quorum is preserving the continuity of knowledge. Suppose we don’t have majority quorum and have an environment that comprises five processes. Three of these die and the system keeps processing requests. Later on, two of those dead systems came up again but the two that were working died. We kept working all this time but there systems that came up have no knowledge of what transpired during the time they were down and no ability to get that information. By insisting on a working majority, we can be sure that there will be one member in common with the old group that still holds the information that is needed to bring the restarted systems up to date.
Introducing Raft
Raft is a consensus algorithm designed for managing a replicated log. It was created at Stanford University in 2014 by Diego Ongaro and John Ousterhout. It was created as an alternative to Paxos. Paxos, created by Leslie Lamport, achieved fame and widespread use as a distributed consensus algorithm. It also achieved infamy for being difficult to grasp, tricky to implement, and requiring additional work to actually make it useful for applications such as replicated logs (this lead to something called multi-Paxos). Raft was designed with the goal of being equivalent and as efficient as Paxos for log replication but also easier to understand, implement, and validate.
Raft separates the functions of leader election and log replication. Safety, keeping the logs consistent, is integrated into both of these functions.
The Raft environment
Raft is implemented on a group of servers, each of which hosts:
- The state machine (the service that the server provides).
- A log that contains inputs fed into the state machine.
- The Raft protocol.
Typically, this will be a small number of systems, such as 3, 5, or 7.

One of the servers is elected to be the leader. Other servers function as followers. Clients send requests only to the leader. The leader forwards them to followers. Each of the servers stores receiver requests in a log.
Server states
A server operates in one of three states:
- Leader. The leader handles all client requests and responses. There is only one leader at a time.
- Candidate. A server may become a candidate during the election phase. One leader will be chosen from one or more candidates. Those not selected will become followers.
- Follower. The follower does not talk to clients. It responds to requests from leaders and candidates.
Messages
The Raft protocol comprises two remote procedure calls (RPCs):
- RequestVotes
- Used by a candidate during elections to try to get a majority vote.
- AppendEntries
- Used by leaders to communicate with followers to:
- Send log entries (data from clients) to replicas.
- Send commit messages to replicas. That is, inform a follower that a majority of followers received the message.
- Send heartbeat messages. This is simply an empty message to indicate that the leader is still alive.
Terms
The timeline of operations in Raft is broken up into terms. Each term has a unique number and begins with a leader election phase. After a leader is elected, it propagates log entries to followers. If, at some point in time, a follower ceases to receive RPCs from the leader or a candidate, another election takes place and another term begins with an incremented term number.

If a server discovers that its current term number is smaller than that in a received message, it updates its term number to that in the received message. If a leader or candidate receives a message with a higher term number then it changes its state back to a follower state.
Leader election
All servers start up as followers and wait for a message from the leader. This is an AppendEntries RPC that serves as a heartbeat since the leader sends this message periodically even if there are no client entries to append.
If a follower does not receive a message from a leader within a specific time interval, it becomes a candidate and starts an election to choose a new leader. To do this, it sends RequestVotes messages to all the other servers asking them for a vote. If it gets votes from a majority of servers then it becomes a leader.
Leader election: timeouts
Each follower sets an election timeout. This is the maximum amount of time that a follower is willing to wait without receiving a message from a leader before it starts an election. Raft uses randomized election timouts. The election timeout is a random interval, typically in the range of 150–300ms and reduces the chance that multiple servers will start elections at the same time.
When a follower reaches the election timeout without hearing from the leader, it starts an election to choose a new leader. The follower:
- Increments its current term
- Set itself to the candidate state.
- Sets a timer
- Sends RequestVote RPCs to all the other servers
If a server receives a RequestVote message and hasn’t yet voted, it votes for that candidate and resets its election timeout timer.
Once a follower receives votes from the majority of the group, including itself, it becomes the leader and starts sending out AppendEntries messages to the other servers at a heartbeat interval. Receiving votes from a majority of group members ensures that only one leader will be elected.
The system continues operating like this until some follower stops receiving heartbeats, reaches an election timeout, and starts another election.
It is possible that a candidate receives an AppendEntries message while it is waiting for its votes. This means that another server is already acting as the leader since only leaders can send AppendEntries messages. The candidate looks at the received message and makes the following decision:
A. If the term number in the message is the same or greater than the candidate’s term then the candidate will recognize the sender as the legitimate leader and become a follower.
B. If the term number in the message is smaller than the candidate’s term then the candidate rejects the request and continues with its election.
Elections: Split votes
It’s possible that two or more nodes reached their election timeout at the approximately the same time and both became candidates and started elections with neither receiving a majority vote. If this situation arises, both of the nodes will time out waiting for a majority (election timeout) and each will start a new election.
The same mechanism of randomized timeouts that was put in place to reduce the chance of concurrent elections ensures that this split vote process does not happen indefinitely. Having multiple nodes repeatedly pick the same election timeout after a split vote is extremely unlikely (and a sign of a horribly bad random number generator).
Log Replication
Once a leader has been chosen, clients only communicate with that leader. Other servers will reject client requests and may respond with the identity of the current leader. Clients send requests to leaders. If the request is a query – something that will not change the state of the system – the server can simply respond to the client.
If the request will result in a change to the system, the leader will add the request to its log and send an AppendEntries message to each of the followers (re-sending as needed to ensure reliable delivery).
Each server maintains a log of requests. This is an ordered list where each entry contains:
- The client request (the command to be run by the server).
- The term number when the command was received by the leader (to detect inconsistencies)
- An integer that identifies the command’s position in the log.
A log entry is considered committed when the message has been replicated to the followers. The leader can then execute the request and return any result to the client. Followers are also notified of committed log entries so that they can execute the same requests and keep their state machines in sync with the leader and each other. A leader notifies followers of committed messages in future AppendEntries messages.
Log replication: consistency checks
For replicated state machines to have the same state, they must read the same sequence of commands from the log. Raft enforces a log matching property that states if two entries in two logs have the same index number and term then the log entries will contain the same command and all previous entries will be identical among the two logs.
When a server sends an AppendEntries message to a follower, the message contains:
- The client request (the command to be run by the server)
- The index number that identifies the command’s position in the log.
- The current term number.
- The index number and term number of the preceding entry in the log.
When a follower receives an AppendEntries message, it does a consistency check:
If the leader’s term (in the message) is less than the follower’s term then reject the message – some old leader missed an election cycle.
If a follower does not see the preceding index and term number in its log then it rejects the message
If the log contains a conflicting entry at that index – a different term number, delete the entry and all following entries from the log.
If all these consistency checks pass then the follower will add the entry to its log and acknowledge the message. This tells the leader that the follower received the message and also validated that its log is identical.
When a log entry has been accepted by a majority of servers, it is considered committed. The leader can execute the log entry and inform followers to do the same.
Log replication: making logs consistent
Normally, we expect that the logs will remain consistently replicated across all servers. Sometimes, however, logs may be in an inconsistent state because a leader died before it was able to replicate its entries to all followers or because followers crashed and restarted.
The leader is responsible for bringing a follower’s log up to date if inconsistencies are detected. It does this by finding out the latest log entry in common between the leader’s and follower’s log (the log matching property discussed earlier).
A leader tracks the index of the next log entry that will be sent to each follower (Raft calls this nextIndex). Initially, and in normal operation, this will be the very latest index in the log. If a follower rejects an AppendEntries message, the leader decrements the value of nextIndex for that follower and sends an AppendEntries RPC for the previous entry. If that is rejected as well, the leader decrements nextIndex again and keeps doing so until it sends the follower a message with an index entry that matches the follower’s. At this point the logs match and the leader can send subsequent entries to synchronize the log and make it consistent.
This technique of going back in the log to find a consistent point means that Raft does not require any special procedures to be taken to restore a log when a system restarts.
Elections: ensuring safety
During the voting phase, a candidate cannot win an election if its log does not contain all committed entries. Because a candidate needs to contact a majority of servers to win the election, every committed entry in its log must be present in at least one of the servers (an entry doesn’t get committed until the majority of servers at that time accepted it).
To enforce this condition, the election process has another decision point. The RequestVotes RPC sends information about the log length and the term of the latest log entry. It applies the following logic:
If a server receives a RequestVotes message and the candidate has an earlier term then the server will reject the vote.
If the term numbers are the same but the log length of a candidate is shorter than that of the server that receives the message, the server will reject the vote.
References
Diego Ongaro and John Ousterhout, In Search of an Understandable Consensus Algorithm, 2014 USENIX Annual Technical Conference, June 2014, pp. 305–319
Presentation video: Diego Ongaro and John Ousterhout, In Search of an Understandable Consensus Algorithm, 2014 USENIX Annual Technical Conference, June 2014.
Video: Designing for Understandability: The Raft Consensus Algorithm, John Ousterhout, August 29, 2016.
Brian Curran, What are the Paxos & Raft Consensus Protocols? Complete Beginner’s Guide, Blockonomi, November 14, 2018.
Leslie Lamport, The Part-Time Parliament, August 2000. This is the original Paxos Paper.
Leslie Lamport, Paxos Made Simple, November 2001.
David Mazières, Paxos Made Practical, Stanford University, 2007
The Raft Consensus Algorithm, Project page @ github: RaftScope visualization and lots of links to papers, videos, and implementations.
Parikshit Hooda, Raft Consensus Algorithm, GeeksforGeeks, 2018