The internet runs on automation, and not all of it is friendly. Automated scripts, or bots, can register thousands of fake accounts, scrape web content, overload services, or execute denial-of-service attacks. Some are used to scalp concert tickets or fake social media engagement; others fill comment sections with spam or probe systems for vulnerabilities.
Security systems can authenticate who someone is, but they cannot always tell what something is. The problem CAPTCHA tried to solve is distinguishing a real human user from an automated process.
This challenge lies at the boundary of computer vision, psychology, and usability. It gave rise to a now-familiar category of tests designed to be easy for humans but difficult for computers.
Origins of the Idea
The roots of CAPTCHA go back to the late 1990s, when the web’s openness invited large-scale abuse.
AltaVista’s Problem
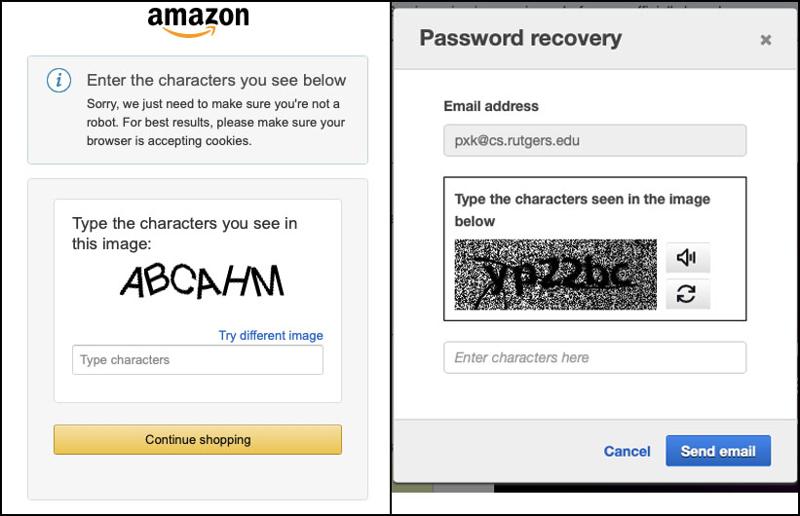
In 1997, Andrei Broder and his team at AltaVista (an early search engine) faced a problem: spammers were automatically submitting URLs to the search engine to boost their rankings. They designed a system that displayed distorted text images and asked users to retype them. Humans could easily recognize the distorted words; OCR software could not. This was the first known use of a reverse Turing test—a test designed to verify that the user is human rather than a machine—to block automation.
Gestalt Psychology and Human Perception
The core insight draws on Gestalt psychology, developed by Max Wertheimer, Wolfgang Köhler, and Kurt Koffka (1920s). Gestalt theory explains how humans interpret visual information holistically rather than as disconnected shapes. The mind tends to fill in missing parts and perceive coherent patterns even in noisy, ambiguous images.
Key Gestalt principles used implicitly in CAPTCHA design:
-
Proximity: we group things that are close together.
-
Similarity: we link elements with similar shapes or colors.
-
Good Continuation: we expect smooth, continuous lines.
-
Closure: we mentally complete partial shapes.
-
Figure and Ground: we separate objects from background.
When text is stretched, occluded, or blurred, humans still “see” letters as wholes; early OCR systems could not. CAPTCHA deliberately exploited this difference.
Formalizing CAPTCHA
In 2000, Luis von Ahn, Manuel Blum, Nicholas Hopper, and John Langford at Carnegie Mellon University developed a formal version of this concept. They coined the term CAPTCHA, short for Completely Automated Public Turing test to tell Computers and Humans Apart.
Their implementation, EZ-Gimpy, displayed one distorted word from a set of 850 common English words and asked the user to type it.
It became popular at Yahoo!, which faced automated account creation at the time.
Independently, Henry Baird (CMU) and Monica Chew (U.C. Berkeley) developed BaffleText (2003), which generated random, non-English text strings with heavy distortion and background clutter. This design eliminated linguistic cues that OCR algorithms might exploit.
Both EZ-Gimpy and BaffleText represent the first generation of text-based CAPTCHAs, designed to exploit weaknesses in OCR systems and leverage human perceptual strengths.
Historical Timeline
| Year | Development | Description |
|---|---|---|
| 1997 | AltaVista image distortion | Andrei Broder and colleagues created an image-based text distortion test to prevent automated URL submissions that gamed search results. This marked the first known use of a reverse Turing test to block bots. |
| 2000 | CAPTCHA coined (CMU) | Luis von Ahn, Manuel Blum, Nicholas Hopper, and John Langford formalized the concept and created EZ-Gimpy, which showed one distorted English word from a fixed list of 850. |
| 2003 | BaffleText (CMU & U.C. Berkeley) | Henry Baird and Monica Chew designed a system that generated nonsense text strings with background clutter to block automated account creation. |
| 2007 | reCAPTCHA introduced | Von Ahn’s team launched reCAPTCHA, combining human verification with digitization of scanned texts. |
| 2009 | Google acquisition | Google acquired reCAPTCHA to use it for digitizing the New York Times archives and improving OCR for Street View data. |
| 2014 | NoCAPTCHA reCAPTCHA (v2) | Google replaced text puzzles with the “I’m not a robot” checkbox and behavioral analysis to assess humanness. |
| 2018 | Invisible reCAPTCHA (v3) | Eliminated the checkbox; background risk scoring replaced explicit challenges. |
| 2024 | AI defeats reCAPTCHA | ETH Zürich team achieved 100% solve rate using the YOLO object-recognition model and simulated human mouse behavior. |
| 2024 | APT28 fake CAPTCHA attack | CERT-UA reported that the Russian-linked APT28 group used counterfeit CAPTCHA boxes to deliver PowerShell malware. |
| 2025 | ChatGPT Agent passes verification | OpenAI’s autonomous ChatGPT Agent was observed completing Cloudflare’s “Verify you are human” test via realistic behavioral mimicry. |
| 2025 | IllusionCAPTCHA | AI-generated optical illusions used as CAPTCHAs |
| 2025 | Orb & Orb Mini | Sam Altman’s Tools for Humanity introduced the Orb, using iris scans for proof of personhood. |
Why we still need CAPTCHAs
Even with better account-level security, we still need a quick way to separate humans from automated clients at interaction time.
-
Preventing automated exploits
CAPTCHAs throttle basic bots that spam forms, brute-force passwords, create mass accounts, or scrape content at scale. They are not a silver bullet but they raise the cost of abuse and reduce noise. -
Minimizing resource abuse
Free trials, API keys, coupon codes, and limited-quantity offers are costly if bots can register at volume. CAPTCHAs help ensure that rate limits and quotas serve people rather than scripts. -
Rate limiting and fairness
Some services use CAPTCHAs as a gate before expensive operations, preserving capacity for real users under load or during an attack. -
Enhancing data quality
Automated bots can skew analytics and pollute datasets by flooding systems with fake inputs, registrations, or interactions. CAPTCHAs help ensure that collected data represents genuine human behavior, which improves decision-making, marketing, and research. -
Human verification in specific contexts
Certain workflows require a human in the loop: online voting and surveys, confirming the authenticity of e-commerce purchases, or preventing ticket scalping and mass reservations for events and restaurants.
Problems with CAPTCHAs
Man-in-the-middle attacks via human solvers
Bots can outsource the puzzle to low-cost humans (CAPTCHA farms). When a site presents a challenge, the bot forwards it to a human solver, receives the human’s answer, and relays it back to the site. This defeats the intended asymmetry without breaking the CAPTCHA itself.
Accessibility
Distorted text and small image tiles are difficult for users with visual impairments. Audio CAPTCHAs exist but are often noisy, language-dependent, and challenging for many users, including those with hearing impairments. Accessibility remains a core weakness.
Improved image and audio recognition algorithms
Modern OCR and computer vision models can read warped text and classify objects in image grids with high accuracy; speech models can transcribe noisy audio prompts. The result is an arms race in which puzzles become harder for humans without stopping advanced bots.
User frustration and abandonment
CAPTCHAs add friction. As challenges became more complex, humans failed more often, especially on mobile devices, leading to repeated attempts and session abandonment. Excessive use of CAPTCHAs degrades user experience and can reduce conversion rates.
reCAPTCHA: Getting value out of CAPTCHA
Luis von Ahn, one of the creators of CAPTCHA at CMU, was aware of a problem Google was having: they were scanning millions of books, newspapers, and magazines but about 30% of the scanned text could not be reliably recognized due to distortions.
This gave him an idea: use that text that computers cannot recognize as a challenge for humans. In 2007, he launched reCAPTCHA, which turned human effort into a productive task.
Each challenge displayed two words:
-
One word whose text the computer already knew (for verification).
-
A second word from a scanned book that OCR software could not interpret.
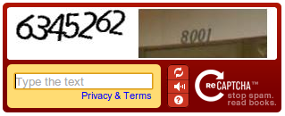
If the user typed the known word correctly, their answer for the second one helped digitize historical texts. When multiple users agreed on an answer, it was accepted as accurate.
Google acquired reCAPTCHA in 2009 and used it for large-scale transcription projects, such as digitizing The New York Times archives, and later for identifying house numbers in Google Street View. (BTW, Luis von Ahn and his team went on to create the Duolingo platform).
By 2014, Google’s own machine learning systems could solve both CAPTCHA and reCAPTCHA images with 99.8 percent accuracy, effectively breaking the system.
Beyond Text: Image and Puzzle CAPTCHAs
The next phase used visual recognition.
Users were asked to identify all images containing specific objects (“bridges,” “buses,” “traffic lights”) or to drag and drop puzzle pieces into place.
These systems took advantage of the then-limited visual reasoning ability of algorithms and of the ubiquity of touchscreens: touching is easier than typing.
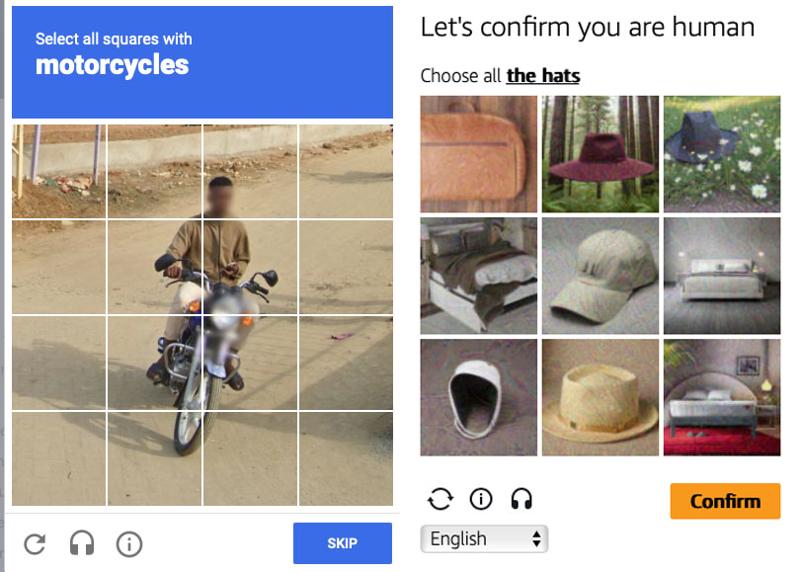
But image recognition AI quickly caught up, and many challenges became more annoying for humans than for bots.
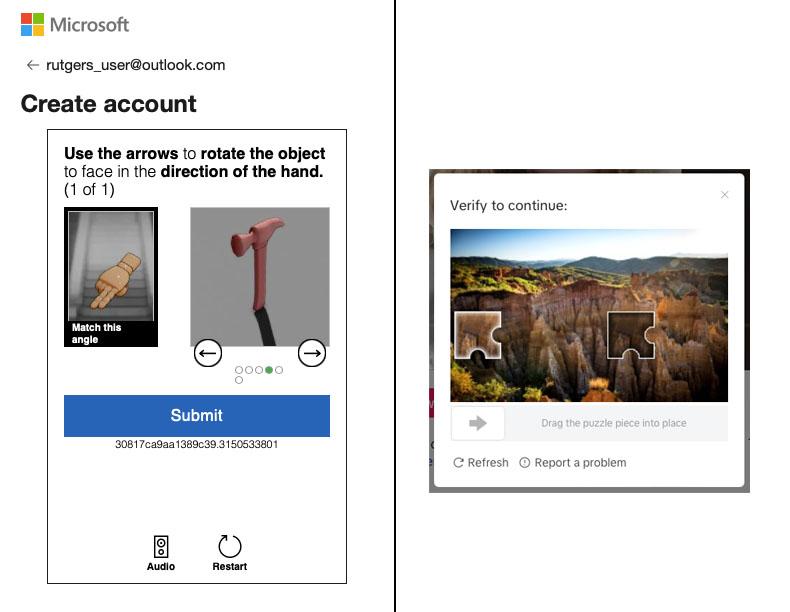
Challenges evolved from image recognition to puzzles that involves aligning images or rotating 3-D renderings of images:
NoCAPTCHA reCAPTCHA (v2)
In 2014, Google introduced NoCAPTCHA reCAPTCHA (v2), designed for a better user experience.
Instead of a distorted image, users simply checked a box labeled “I’m not a robot.”
 Behind the scenes, a server-based risk analysis engine evaluated:
Behind the scenes, a server-based risk analysis engine evaluated:
-
Browser cookies and session data
-
IP address and known bot networks
-
Mouse movement smoothness and acceleration
-
The timing and spatial distribution of clicks
-
Interaction with the page before and after the click
A high confidence score let the user through instantly.
If confidence was low, Google displayed an image-based fallback CAPTCHA. These puzzles came in three forms:
-
Classification (static grid): identify which images in a 3×3 grid match a description such as “select all images with bridges.”
-
Classification (dynamic replacement): similar to the first, but images are replaced after each click until none remain.
-
Segmentation: divide a single image into a 4×4 grid and select all parts that match a prompt, such as identifying all parts of a motorcycle.
These image-based puzzles used real-world photos from Google’s datasets to improve object labeling while providing more diverse human challenges.
Invisible reCAPTCHA (v3)
The next step, Invisible reCAPTCHA, removed even the checkbox.
Google’s system now tracks behavior throughout a session and assigns a trust score between 0 and 1, indicating the likelihood that the user is human. Websites decide how to respond: low scores can trigger a visible CAPTCHA or block access.
While convenient, this method raised privacy concerns, since behavioral data, cookies, and browsing histories contribute to the decision.
The AI Threat
By the 2020s, AI made the CAPTCHA problem worse.
-
In 2024, researchers at ETH Zürich demonstrated that reCAPTCHA v2 could be solved 100 percent of the time using publicly available AI software. They fine-tuned the YOLO (You Only Look Once) object-recognition model, automated repeated trials using VPNs to spoof distinct IPs, and simulated human mouse motion with Bezier curves.
-
In 2025, OpenAI’s ChatGPT Agent passed Cloudflare’s “Verify you are human” test. It behaved like a person, moving the cursor, clicking, and waiting, without ever solving a puzzle. Its human-like behavior fooled Cloudflare’s risk analysis.
The line between bot and human behavior has effectively disappeared.
IllusionCAPTCHA: Fighting AI with AI
Researchers have experimented with IllusionCAPTCHA, which uses AI-generated optical illusions.

Generative models can create complex illusions but typically fail to perceive them. Humans passed such tests 83 percent of the time, while large language models failed completely.
This approach leverages a new asymmetry: humans are still far better at interpreting perceptual illusions than AI systems are.
Fake CAPTCHA Attacks
In late 2024, Ukraine’s Computer Emergency Response Team (CERT-UA) reported that the APT28 (Fancy Bear) group, linked to Russian intelligence, deployed malicious fake CAPTCHAs.
Victims saw what looked like a normal “I am not a robot” checkbox.
Clicking it executed a hidden PowerShell command copied to the clipboard, infecting systems or exfiltrating data.
The attack targeted Ukrainian government workers but highlighted a broader threat: CAPTCHA mimicry as social engineering.
An attack in late 2024 exploited users’ familiarity with evolving CAPTCHA variations. In this case, the instructions to “prove you’re human” asked users to press the Win key + R, followed by Ctrl+V, followed by Enter.
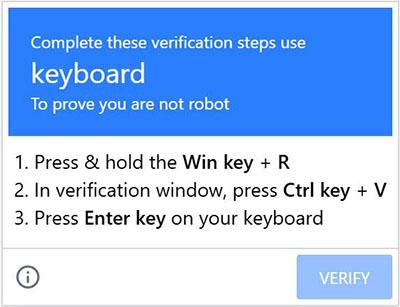
A malicious PowerShell script is copied to the clipboard. The Win+R key sequence opens the Run dialog box in Microsoft Windows; Ctrl+V pastes the contents of the clipboard; and Enter runs it. You can read more details about this attack here.
Alternative Human Tests
Other verification approaches have appeared:
-
Email or SMS verification: a one-time code sent to a known address or number.
This increases friction but still allows automated enrollment using disposable accounts. -
Timing analysis: human typing and form completion times are irregular; bots can simulate delays but rarely with the same variability.
These methods supplement but do not replace CAPTCHA; they simply raise the cost of automation.
The Orb: Biometric Proof of Personhood
Recognizing that behavioral and perceptual tests may soon fail, Tools for Humanity, founded by Sam Altman (also CEO of OpenAI), developed the Orb and Orb Mini. The devices scan a person’s iris to create a unique, privacy-preserving identifier stored as a token on the Worldcoin blockchain.
The idea is that in a world of AI agents indistinguishable from people, only a biometric signature can prove humanness.
However, this approach raises significant concerns:
-
Privacy: biometric data is highly sensitive and permanent—unlike passwords, you cannot change your iris if it’s compromised
-
Surveillance: centralized databases of biometric identifiers could enable mass tracking
-
Consent and coercion: in some contexts, biometric verification could become mandatory, limiting individual autonomy
-
Security: biometric databases are high-value targets for attackers
Despite these concerns, the Orb reflects the same fundamental problem that CAPTCHAs addressed: how to know that a real person is on the other end.
A Post-CAPTCHA World
AI can now defeat nearly every CAPTCHA variant. The original principle, find something easy for humans but hard for computers, has inverted.
The future of human verification will rely on:
-
Behavioral biometrics: patterns in typing, movement, or device usage.
-
Contextual trust: consistent device, location, and network patterns.
-
Cryptographic proofs of personhood: tokens, attestations, or blockchain-based credentials.
In the coming years, the relevant question will not be “Are you human?” but rather “Is this entity authorized and accountable for its actions?”
References
-
Irfan Mehmood & Kamran Mahroof, ‘Yes, I am a human’: bot detection is no longer working – and just wait until AI agents come along, The Conversation, Dec 20 2024.
-
Are you a robot? Introducing “No CAPTCHA reCAPTCHA, Google Search Central Blog, Dec 3 2014.
-
ETH Zürich, Breaking reCAPTCHA v2 using YOLO, arXiv 2409.08831 (2024).
-
OpenAI’s ChatGPT agent casually clicks through ‘I’m not a robot’ verification test, Ars Technica, Jul 25 2025.
-
AI-generated optical illusions can sort humans from bots, New Scientist, Feb 2025.
-
New Cyber Attack Warning—Confirming You Are Not A Robot Can Be Dangerous, Forbes, Oct 2024.
-
The Orb, Tools for Humanity.
-
Elise Annett, James Keagle, & James Giordano, The Orb’s Eye: Seeing the National Security Implications of Iris Based ‘Proof of Humanity’, Institute for National Strategic Studies, July 1, 2025.